Document Classification for Feedback, Tickets, Posts & PDFs
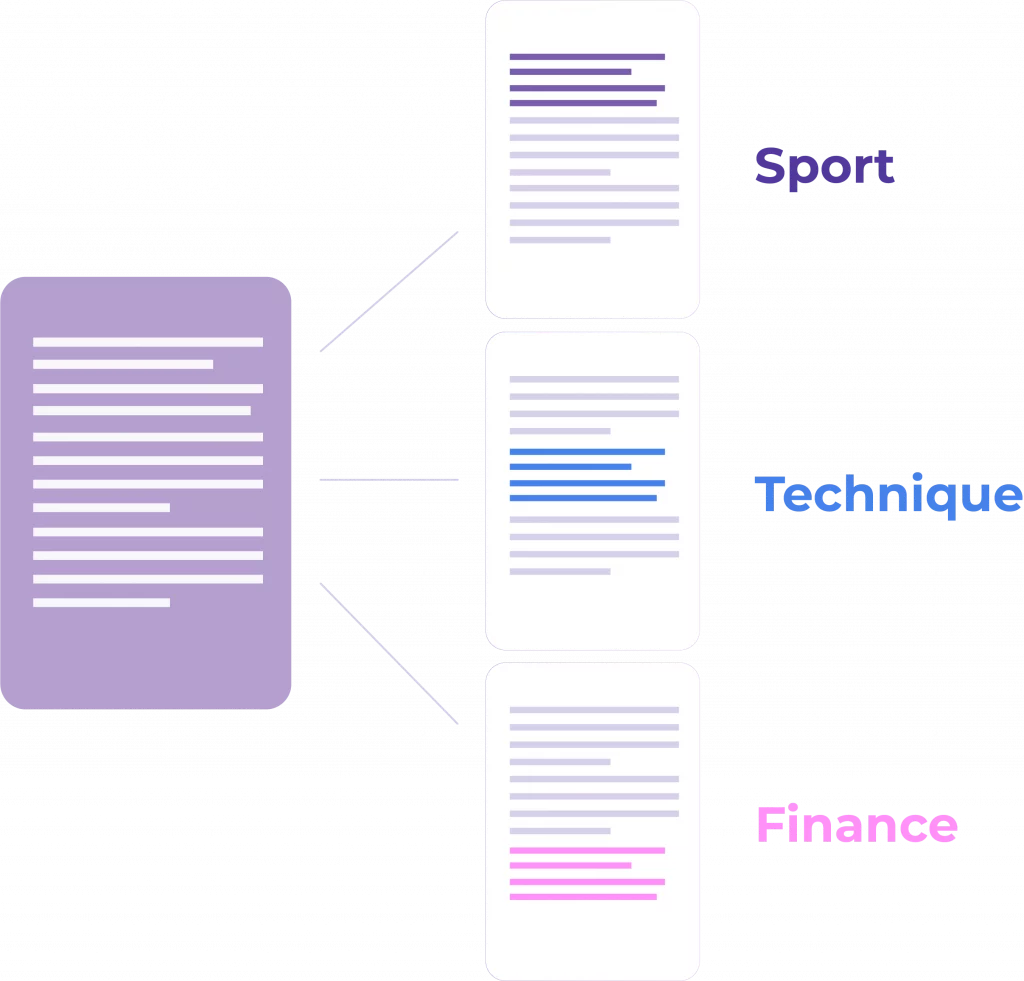
Text in documents or social media data that needs to be classified is the key to sorting content into useful categories. With this in mind, SentiDigital offers a robust document classification tool built for Natural Language Processing (NLP) tasks. In practice, it streamlines how teams organize feedback, tickets, posts, and PDFs into labels that actually drive decisions.
For example, it can train machine-learning models for topic detection, technical vs. non-technical issues, or negative review detection. Additionally, it supports zero-shot document classification, so you can start with custom labels even without training data. When you’re ready, you can switch to supervised training to boost precision on your domain. Moreover, multilingual support (English, French, Arabic) ensures consistent labeling across markets.
Beyond labeling, SentiDigital provides confidence scores, confusion insights, and error analysis; as a result, you can quickly spot ambiguous items and refine labels. Moreover, human-in-the-loop review lets you accept, edit, or reject suggestions, which consequently improves future accuracy. From there, exports (CSV/PDF) and an API integrate results into BI tools, CRMs, and data warehouses.
Typical use cases include: routing support tickets by intent, prioritizing product feedback by theme, flagging compliance risks, tagging UGC by sentiment, and clustering research notes for faster synthesis. Ultimately, SentiDigital turns messy text into reliable datasets and dashboards so teams move from guesswork to measurable action in days, not months.